How I locally fine-tuned Whisper using my own voice data and minimal effort
Published on · 6 min read in development , AI , machine-learning
Off-the-shelf Whisper models are impressive. Whisper is able to translate and transcribe a wide variety of languages while using consumer hardware. One reason it’s so good came from being able to leverage way more semi-self-supervised data than models before it, using something like 680,000 hours of recorded audio clips and transcriptions. That data includes many languages (to varying degrees of accuracy) meaning the model can accurately process a wide range of accents, languages, and recording conditions well. But it’s not perfect. Depending on the model variant, the WER is like 9.3% for English and because the model was released in 2023, so too is the model’s vocabulary. Anything that wasn’t included in the training data won’t be transcribed well, meaning sentences that have new word, new technical jargon or slang won’t be particularly accurate.
So other than waiting around for OpenAI to release a new version trained on new data, a potential fix for that is fine-tuning. It’s a lighter weight process for updating model weights, reusing the core weights of the original model and greatly reducing the complexity, cost and resourcing otherwise required when starting from scratch.
However fine-tuning still requires data. And not just any data, but high quality data that actually can be used to address any of the models shortcomings. Getting this data can be quite a challenge for even well funded teams looking to improve the model.
The natural starting point is one of the established open datasets: Common Voice, LibriSpeech, VCTK, or one of the many derivatives built on top of them. They’re free, reasonably well-documented, and genuinely useful with some extra processing.
But there is a catch: almost all of them are read speech (Common Voice does have “spontaneous speech” now, though the dataset is much smaller for now), the quality of audio greatly varies and accuracy of transcriptions/metadata is also not guaranteed.
A read-speech corpus has a particular cadence. A participant sits down, reads a sentence off a screen, waits for the recording light, and reads the next one. The recordings are clean, carefully segmented, and nothing like how people talk when they are thinking, explaining, or in the middle of a conversation. The vocabulary is also frozen at collection time. In my case, I tend to speak a lot of technical jargon, meaning words like LoRA, ROCm, GPT, or any number of domain-specific words simply do not exist in datasets assembled five years ago.
Dataset quality is generally improving though, with iniatives like Mozilla’s Data Collective and Common Voice helping push the market forward for ASR/voice datasets. But the realistic question is whether those datasets contain enough material that matches your specific use case. Accent, domain, speaking style, acoustic environment all need to be considered. For my usecase, I wanted my voice and a specific list of words to be better understood which these datasets wouldn’t really help with.
That means needing to collect and process my own data. This gives me the most control but also the most work to do. Getting tens of hours of high quality, transcribed and relevant data isn’t a trivial endeavour. I don’t have the resources to just pay someone to have a conversation and then painstakingly transcribe the audio. Nor would that actually reflect my voice. Hiring a professional annotation service is also out of the question because of cost and effort involved and costs wouldn’t scale if I wanted to keep adding to the dataset.
After looking at other projects that aide in voice collection, I realized it’s probably simpler for me to just create my own solution. I didn’t want to learn a specific workflow and then still need to do additional bespoke processing, I didn’t want to use any online/cloud services and I wanted to make the most out of the hardware I was already using.
So I created Listenr. Initially, I focused on the the collection, transcribing and validation of conversational audio and then turned it into an full service, end-to-end fine-tuning pipeline.
The dataset-building side of the project works by streaming an audio source (like a microphone) that’s always on, passing the data to a VAD-enabled ASR service that generates the intial transcipt, saves the audio and then uses a LLM to further improve the raw transcript with a series of prompts and helpers (I can pass in a list of words I want it to generally watch out and replace).
Automating the Hard Part
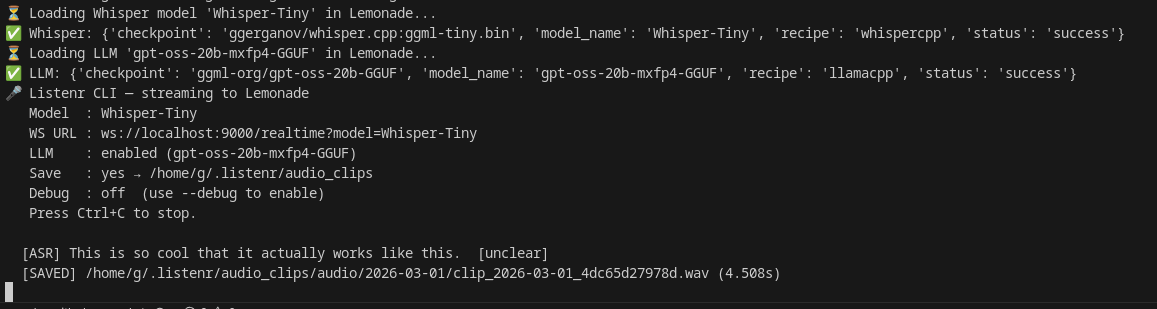
Whisper is already good enough to use to get a raw transcript in real time. Whisper-Tiny or Whisper-Base are smallest models and easily run on a dedicated GPU. They’re not super accurate, but that’s fine for this case - we leverage VAD and the small model to optimize what audio clips are actually being saved to disk. Otherwise, there’d be way too much useless data being saved and a more complex audio processing/segmentation step.
The raw transcripts can then also being improved using an LLM. Not just any LLM either, but local, private ones. Local LLMs are now capable enough to clean up the rough edges of a raw ASR transcript by fixing punctuation, correcting obvious homophones, expanding contractions, flagging poorly structured transcripts, and using conversation context to help shape transcripts.
Neither of those steps requires a human in the loop for a first pass and when continuously running in the background, a growing, labeled corpus of my own voice data naturally grows over time. And with none of the icky privacy-infringing services or ballooning costs that commerical tools might incur.
Personal Corpus to ASR dataset
So to reiterate, Listenr’s dataset building flow involves
- Capture — mic audio streams continuously; silence detection splits it into individual clips.
- Transcribe — each clip runs through Lemonade that has VAD and Whisper.cpp running locally for real-time transcripts
- Post-process — a local LLM also running on Lemonade that refines the raw transcript: fixes punctuation, corrects obvious errors, tags
[unclear]segments, and normalises spacing and contractions.
What’s next is storing and packaging the data. The audio clip and corrected transcript are appended to a JSONL manifest on disk. And then when ready to package, a build-dataset command builds train/dev/test splits in HuggingFace or Common voice-styled datasets format.
The mainifest.jsonl looks something like this:
{
"uuid": "dbee80fdf678",
"timestamp": "2026-03-05T01:21:38.611439+00:00",
"audio_path": "~/listenr/audio_clips/audio/2026-03-04/clip_2026-03-04_dbee80fdf678.wav",
"raw_transcription": "I generally prefer Gemma.",
"corrected_transcription": "I generally prefer Gemma.",
"is_improved": false,
"categories": [
"note"
],
"whisper_model": "Whisper-Base",
"llm_model": null,
"duration_s": 1.878,
"sample_rate": 16000
}
{
"uuid": "3125bf40c882",
"timestamp": "2026-03-04T01:21:41.081500+00:00",
"audio_path": "~/listenr/audio_clips/audio/2026-03-04/clip_2026-03-04_3125bf40c882.wav",
"raw_transcription": "Clode code is a tool.",
"corrected_transcription": "Claude code is a tool.",
"is_improved": true,
"categories": [
"command"
],
"whisper_model": "Whisper-Base",
"llm_model": "gpt-oss-20b-mxfp4-GGUF",
"duration_s": 0.085,
"sample_rate": 16000
}
JSONL is a handy format for querying and working with, tools like jq and virtually all modern programming languages are able to manipulate and work with it out of the box.
And so that’s how Listenr enables anyone to create their own dataset in as painless and time-reducing way as possible. There’s still glitches and the processing pipeline isn’t perfect, but it defientely beats manually transcribing from scratch or otherwise processing large audio files.
But that’s also just the start. Listenr is a end to end fine-tuning app, but I’ll write about that how that works in the next blog post.
To wrap it all up, Listenr is local-only, never using cloud or paid services. No audio or transcripts leave your machine. It also leverages the giants before it, Whisper, Lemonade, LLMs that others have put into the open.
The best way to get your data is to grow it little by little each day/week/month. Reviewing the manfiest is key to see if your setup is working correctly, and address issues as they appear.
The harder problem of getting enough data to meaningfully move WER is a game of time. But at least it’s mostly automated now.
In the next post: getting AMD GPUs to cooperate for the actual fine-tuning run — ROCm, Docker group IDs, the specific pytorch image tag that finally worked, and the training loop output.