Quick Thoughts
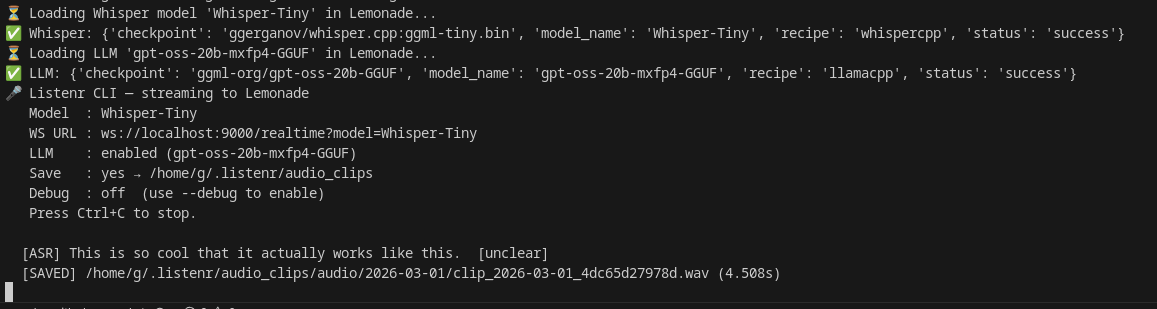
Off-the-shelf Whisper models are impressive but struggle with personal vocabulary, accents, and jargon not present in their training data. This post covers why standard open datasets fall short for personal fine-tuning and how I built Listenr to continuously capture and transcribe my own conversational audio as a training set.